
The Ambition
Every engineering student builds a game at some point. It is practically a rite of passage. When my four friends and I (all CI2 students in the Génie Informatique program at FSTS) set out to build DeepDame, our initial plan was straightforward: create a modern, real-time multiplayer checkers game. We wanted the standard features: secure JWT authentication, friend lists, matchmaking, and a solid AI to play against.
But as we began mapping out the requirements, our conversations shifted from what we were building to how much it could handle.
We realized that building the game logic was only half the battle. The real engineering challenge lay in the infrastructure. We didn't just want to build a functional application; we wanted to build a system capable of surviving real-world scale. That is when we set the core ambition that would define the entire project and push our team to our technical limits: DeepDame had to support 10,000 concurrent players.
Hitting that 10k mark (essentially tackling our own iteration of the classic C10k problem) meant we couldn't just rely on a simple monolithic backend and a basic WebSocket server. Maintaining 10,000 active, stateful connections in real-time requires a completely different approach to system design.
This single ambition transformed DeepDame from a fun university project into a deep dive into distributed systems. It forced us to abandon safe, comfortable architectures and instead engineer an enterprise-grade backend capable of handling massive throughput without buckling. Here is how we designed a system to turn that ambition into reality.
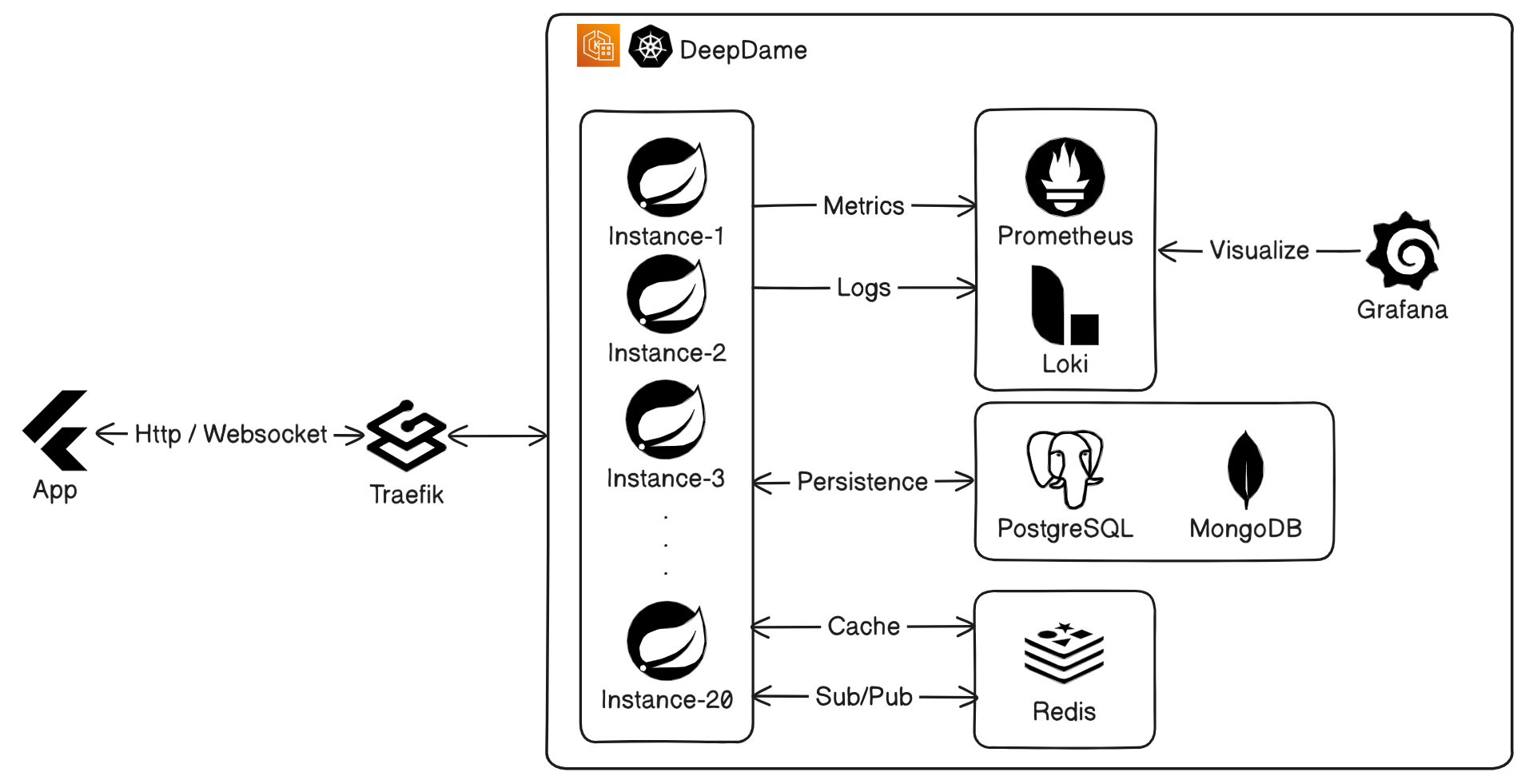
The Architecture: Designing for Scale and Sanity
To support 10,000 concurrent players without our servers catching fire (and without burning ourselves out) we had to be highly strategic about our tech stack. We broke our architecture down into three core pillars: a unified client, a highly decoupled backend, and a rigorous observability layer.
Flutter (Write Once, Run Everywhere)
As a team of five students, we did not have the bandwidth to maintain separate codebases for Web, Android, and iOS. We chose Flutter to build a single, unified frontend. This "write once, run everywhere" approach allowed us to iterate incredibly fast on the UI and game logic. More importantly, it meant we only had to implement and debug our complex STOMP/WebSocket connection logic once, ensuring a consistent real-time experience across all platforms.
Persistence, Caching, and Real-Time Events
Our backend had to juggle historical data, highly relational user states, and ultra-fast real-time messaging. We chose Spring Boot as our core framework to orchestrate this complexity, stitching together specialized tools for each specific job:
- Polyglot Persistence: We split our data layer. PostgreSQL handled our structured, relational data (user accounts, friend lists), while MongoDB swallowed the massive, unstructured documents of completed game histories.
- The Real-Time Protocol: We didn't just use raw WebSockets; we implemented STOMP (Simple Text Oriented Messaging Protocol) over WebSockets. This gave us a structured pub/sub mechanism right out of the box, making it infinitely easier to route specific real-time events; like sending a game invitation or transmitting a checker piece's movement.
- State & Sync: Redis was the glue holding our distributed system together. We used it for aggressive in-game caching and leveraged Redis Pub/Sub to keep our independent server replicas perfectly synchronized.
- Communication: We integrated standard SMTP for asynchronous background tasks like transactional emails and account verification.
The Secret Weapon, Observability (The LGTM Stack)
You cannot confidently scale to 10k users if you are flying blind. When things break at that scale, logging into individual servers to read text files is impossible. We deployed a stripped-down LGTM stack (Loki, Grafana, Prometheus) directly into our cluster.
We didn't just spin up simple containers, either. We fully integrated this stack into Kubernetes:
- We provisioned PVCs (Persistent Volume Claims) to guarantee our logs and metrics survived pod restarts.
- We configured dedicated Services and Deployments for data scraping.
- We exposed Grafana through a LoadBalancer, giving us a centralized, highly available dashboard to watch our system's CPU, memory, and WebSocket connection counts in real-time as we pushed the load higher.
Stress Testing with Grafana k6
Designing for 10,000 concurrent players is one thing; proving the system can actually handle them is another. We couldn't exactly ask 10,000 friends to log in at the same time, so we turned to Grafana k6 to simulate the chaos.
Deploying in the Cloud with AWS EKS
Moving from a local development environment to a production-grade cluster is where the "DeepDame" ambition met reality. To provide the stability and networking throughput required for 10,000 concurrent players, we chose Amazon Elastic Kubernetes Service (EKS).
Provisioning with eksctl
We treated our infrastructure with the same rigor as our code. Using eksctl, we spun up a managed Kubernetes control plane, allowing us to focus on our application rather than the underlying master nodes. This gave us a repeatable, "infrastructure-as-code" approach to deployment.
The Cluster Muscle
To handle the heavy lifting (especially the thousands of simultaneous STOMP connections and the high-frequency Redis operations) we deployed a robust cluster consisting of 4 worker nodes. Across these nodes, we had a combined:
- 32 CPU Cores: Providing plenty of headroom for our server replicas to process game logic.
- 64 GB RAM: Ensuring our Redis cache and observability stack had enough memory to breathe under heavy pressure.
Eliminating the Bandwidth Bottleneck
One of the most critical lessons we learned during testing was that environment matters. Initial tests from our local machines were skewed by local bandwidth limits. To get "clean" data, we shifted our Grafana k6 testing scripts directly into the AWS environment.
By load testing from within the AWS console/backbone, we eliminated external network latency and ISP throttling. This ensured that every millisecond of latency we measured was a true reflection of our application's performance, not a side effect of a weak internet connection. This "internal" testing approach was the final piece of the puzzle that confirmed we could hit our 10k player milestone.
The Look Back: Reality, Rushed Decisions, and Lessons Learned
Building DeepDame was easily the most challenging project our team has tackled, entirely because we crammed a massive distributed systems architecture into a brutal two-week deadline.
Looking back, the pressure of that timeline forced our hand, revealing the inexperience of our team at the time. If I were to do this again, the biggest architectural change wouldn't be in the cloud; it would be in the code. We rushed directly into horizontal scaling (spinning up EKS nodes and load balancers) before we ever stopped to consider vertical scaling and application-level optimizations.
Because we were so focused on the infrastructure, we overlooked fundamental database and framework inefficiencies. We didn't hunt down SQL N+1 query problems. We left default framework configurations running (like having "Open-In-View" (OSIV) enabled) which tied up database connections unnecessarily. We completely ignored connection pool tuning and connection acquisition times.
The cost of this premature horizontal scaling was incredibly high, both in terms of monetary cloud bills and raw development time. Throwing more servers at unoptimized code is an expensive band-aid, and we paid that price in long nights and complex Kubernetes debugging.
The 6k Reality Check
Due to the strict two-week time constraint, we actually ran out of time before we could officially validate the 10,000 concurrent user mark. The maximum load I was able to successfully push through the AWS console before the deadline hit was 6,000 concurrent players.
While it wasn't the 10k we set out for, hitting 6k active WebSockets on a student project built in 14 days is a massive victory. Looking at the resource headroom and the Grafana metrics during that 6k test, I firmly believe the architecture we built could have smoothly passed the 10,000 user mark if we had just a few more days to test and tweak.
The Ultimate Takeaway
When you look at the final product (a Flutter client, an LGTM observability stack, polyglot persistence, Redis pub/sub, and EKS deployments) it’s a lot. Too much, honestly, for two weeks.
The most important lesson I took away from DeepDame isn't about WebSockets or Kubernetes. It is a simpler, more fundamental rule of engineering: Never bite off more than you can chew... unless your primary goal is to learn something.
We bit off an enormous amount with this project. We struggled, we made rookie mistakes with scaling, and we barely slept. But because we aimed for a ridiculous 10,000-player scale, we learned more about cloud infrastructure, system design, and real-world bottlenecks in 14 days than we ever would have building a "safe" standard web app. And for that, every rushed decision was completely worth it.
The team
Other members of the team wrote their own articles about Deepdame, @Amine was the one who wrote the whole flutter client from the ground up in 2 weeks, even though he didn't know how to use flutter (his article). And @Abdellah wrote a huge part of the backend, including the game logic, and also led the development of a new client (his article). @Hajar spent sleepless nights writing the admin dashboard and contributing thousands of lines to the new backend, and @Yasmine wrote part of the authentication. I'm forever grateful for the opportunity to work alongside such talented and hardworking individuals.
P.S. An Open-Source Spin-Off
Setting up Redis Pub/Sub to keep our server replicas in sync was notably tedious. I was surprised to find that spring-data-redis doesn't have a convenient @RedisListener annotation out of the box to handle message routing. Riding the momentum from this grueling two-week sprint, I decided to fix that myself. I implemented the annotation and submitted it to the official Spring repository across two Pull Requests... but that is a story for another article!